Table 2 Summary of input parameters and assumptions in the Monte Carlo simulation of the SCDS results adjusted for outcome misclassification, selection bias and confounding
Input Parameters | Distribution | Source (reference) |
|---|---|---|
Outcome misclassification (information bias) | ||
Observed exposure: mercury concentration in maternal hair (mg/g) | Meanx = 6.9, SDx = 4.5 | Myers et al., 2003 (7) |
Observed outcome: Score on Boston naming test | Meany = 26.5, SDy = 4.8 | Myers et al., 2003 (7) |
Observed b1 | N (-0.012, 0.046) | Myers et al., 2003 (7) |
Observed b0 | = 26.5 - 6.9 × Observed b1 | Derived using standard linear regression formula (b0 = |
P1: proportion of exposed with a1 (negative) adjustment | U (0.1,0.3) | Hypothetical (no data available) |
P2: proportion of exposed with a2 (positive) adjustment | U (0.1,0.3) | |
a1: relative adjustment in outcome for proportion p1 of subjects | U (0.0,1.95) | Hypothetical (no data available), limits chosen as to allow BNT score vary between 0 and 60 |
a2: relative adjustment in outcome for proportion p2 of subjects | U (0.0,1.95) | |
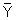 -b1
-b1
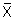 )
)Selection bias | ||
|---|---|---|
Observed exposure: mercury concentration in cord blood (mg/L) | See above | |
10,000 vectors (Meany, Sdy, b0, b1) adjusted for information bias | Output of Information Bias module | |
Number of subjects included in the analysis | 643 | Myers et al. 2003 (7) |
Number of eligible subjects | 1480 | Calculated as 740 × 2 (740 are ~50% of eligible population (7) |
Number of subjects excluded from the analysis | 837 | Calculated as 1480 - 643 |
Relative difference between mean exposure of subjects not included and mean exposure of included subjects | U (-5%,5%) | Hypothetical (no data available) |
Relative difference between mean outcome of subjects not included and mean outcome of included subjects | U (-10%,10%) | Hypothetical (no data available) |
Slope multiplier (to get to slope of non-included subjects) | U (0,2) | Hypothetical (no data available) |
Confounding | ||
|---|---|---|
10,000 vectors (Meanx, SDx, Meany, SDy, b0, b1) adjusted for information and selection bias | Output of Selection Bias Module | |
Pearson correlation between confounder (WAIS) and exposure | U (-0.5, 0.5) | Hypothetical (no data available) |
Pearson correlation between confounder (WAIS) and outcome | U (0.2, 0.8) | Hypothetical (no data available) |